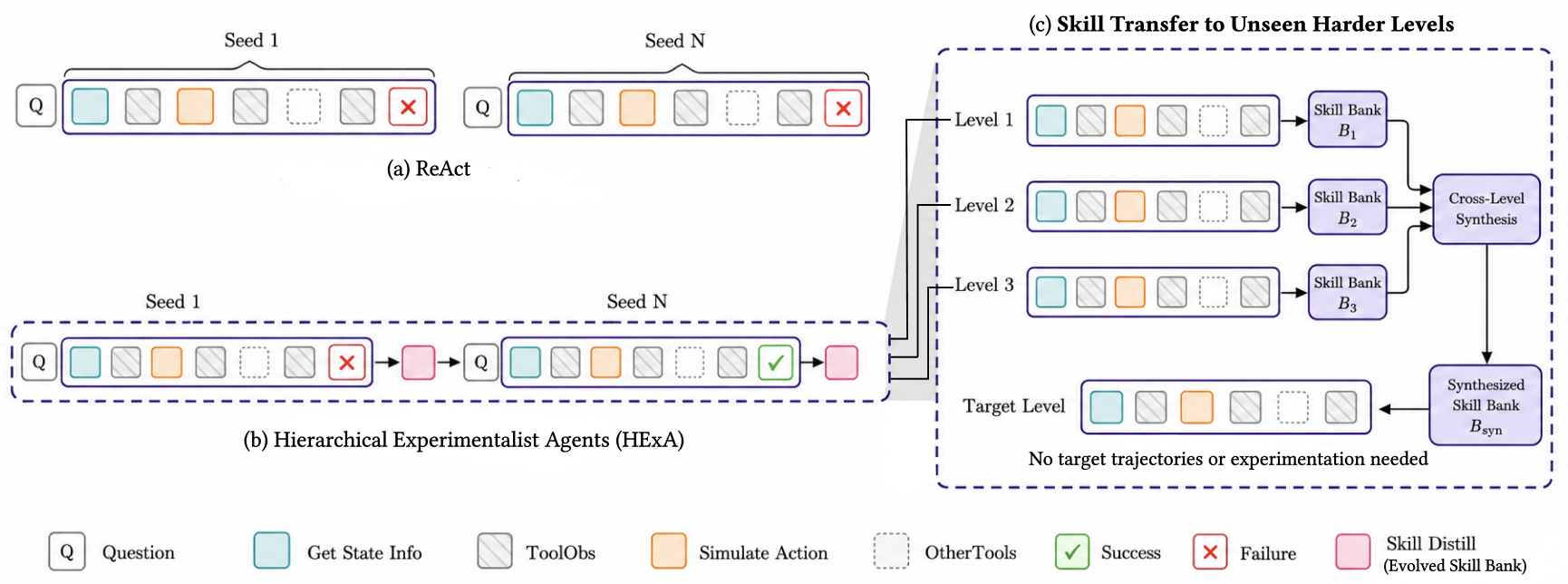
Large language models (LLMs) are increasingly used to take action or augment human decision-making, yet most systems rely on parametric knowledge acquired by imitation, optionally supplemented with fixed data, retrieval, or search. However, this paradigm breaks down in novel domains and on sophisticated queries that cannot be answered from prior knowledge alone: knowing the laws of physics, for instance, does not by itself enable LLMs to answer queries about or complete long-horizon tasks in a complex physical system without explicit interactions in a physics simulator. Thus to solve such novel problems generally, agents should have the fundamental ability of active experimentation—to explore and gather targeted query-specific data or general principles about the unseen environments and to acquire new reusable skills by learning from these diverse interactions and experiences.
We thus introduce Hierarchical Experimentalist Agents (HExA), a novel in-context, experiment-centric self-improvement framework that (1) iteratively designs and refines query-relevant experiments; (2) incrementally learns from experiences a library of reusable and composable skills that accelerate experimentation within and across tasks; and (3) integrates the experimental data to effectively take actions or answer queries. Being entirely in-context and training-free, HExA can be used with any models, including black-box frontier models—enabling them to self-improve while co-evolving the skills using progress and efficiency rewards, interaction feedback from correct, incorrect, and partial rollouts, and experimental interventions, all without any reliance on offline data, oracle supervision, or external teacher guidance.
We also introduce InterPhyre, a 2D procedural physics simulation and embodied reasoning environment with additional tool-call and intervention APIs to enable agents to propose experiments and test hypotheses—designed to better evaluate and measure the ability of agents to learn from experimentation. On the hardest levels of InterPhyre, frontier models like Claude Sonnet 4.6 only achieve 2% success rate while HExA using experimentation-centric learning improves the same model to a maximum success rate of 77%. We also show similar improvements across all experiments with smaller open-weight models and over other agentic baselines like ReAct and Reflexion. The agent also achieves 44% success by not doing any active experimentation and using only skills that were learned and transferred from easier levels, demonstrating reusability and generalization. Our experiments show that current LLM agents still struggle in these settings, leaving a large room for improvement. HExA is a step toward scalable learning mechanisms that let agents learn through active experimentation and interaction while acquiring evolving skills, which remains a core challenge for building generalist agents.
InterPhyre is a 2D procedural physics benchmark built so that solving a task requires
interaction, not recall. In every level the agent places a red ball at (x, y, r); the
simulator then runs forward and checks a level-specific success predicate. The catch: outcomes depend on
contact chains, lever mechanics, and collision timing that cannot be read off a static scene
description — the agent must run experiments to discover them. The curriculum ships
25 levels × 10,000 pre-validated seeds = 250,000 certified task instances, plus a
snapshot/restore intervention API for paired counterfactual rollouts.

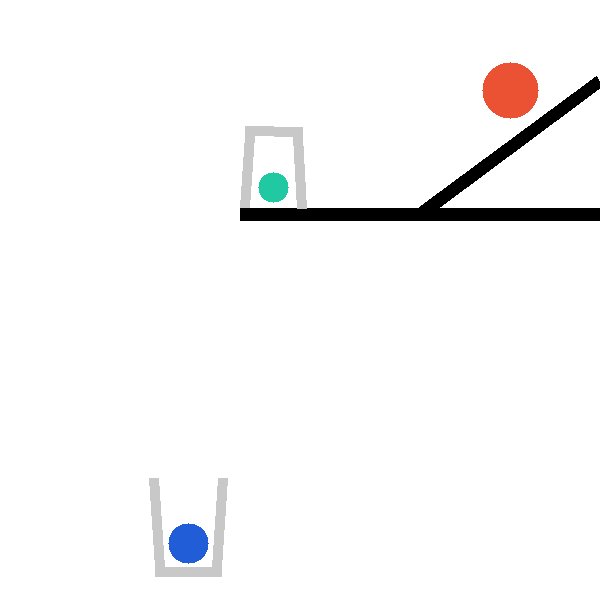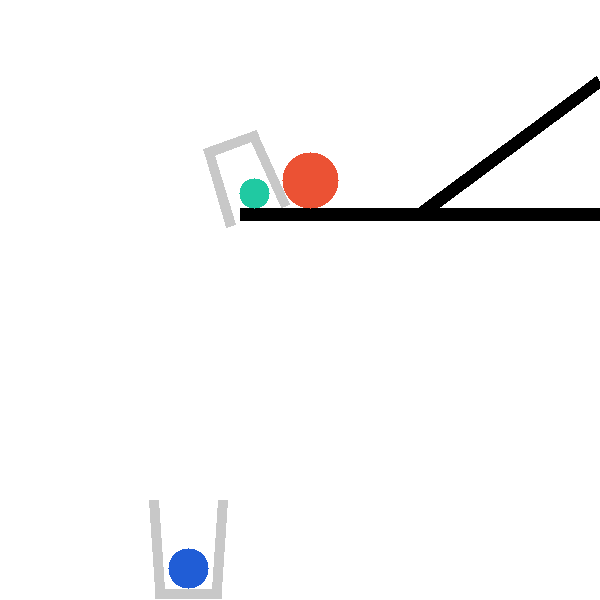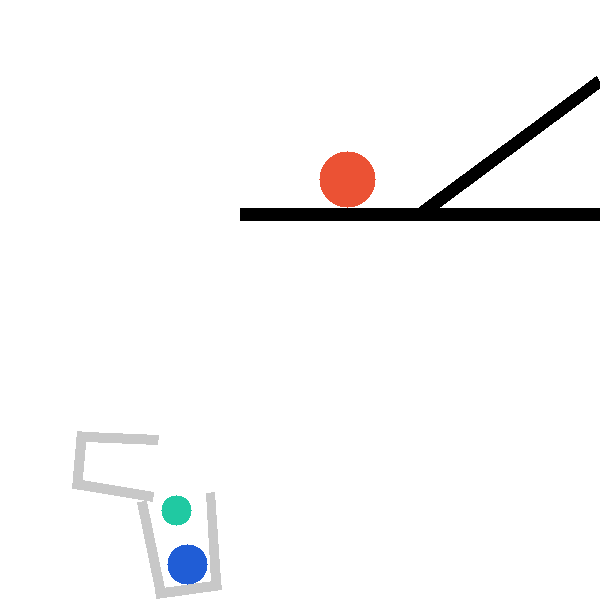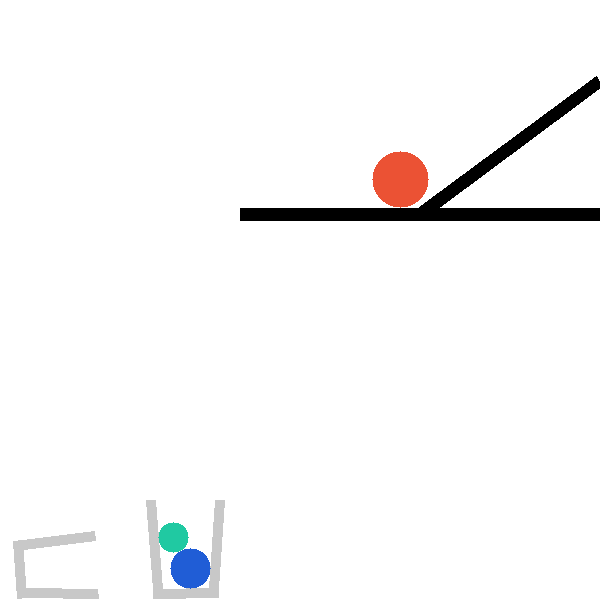


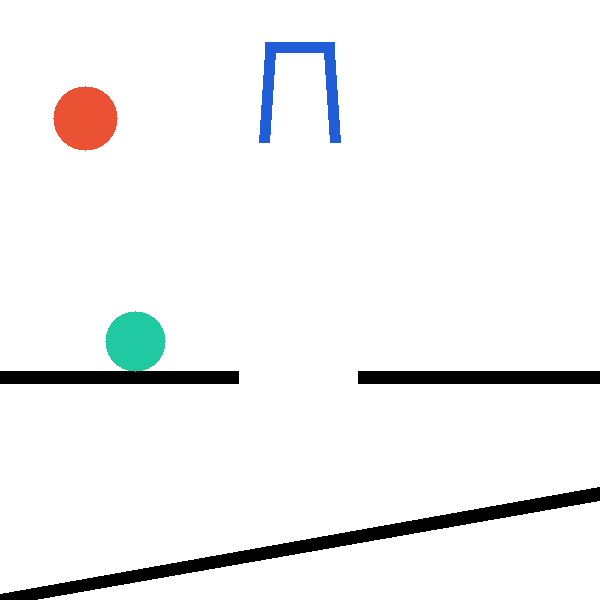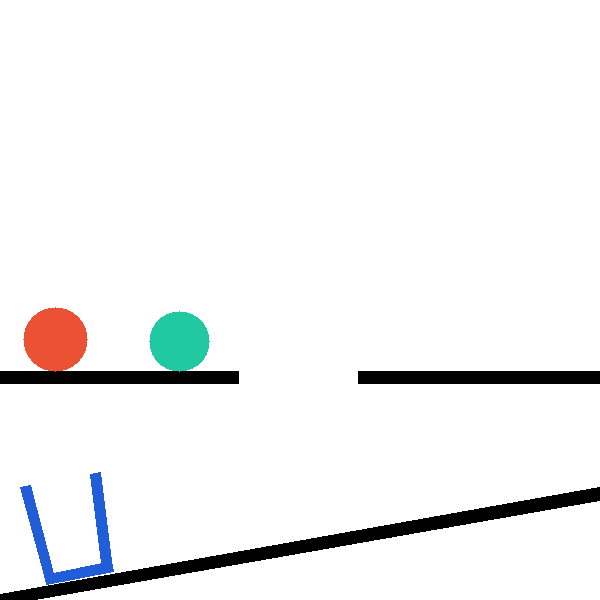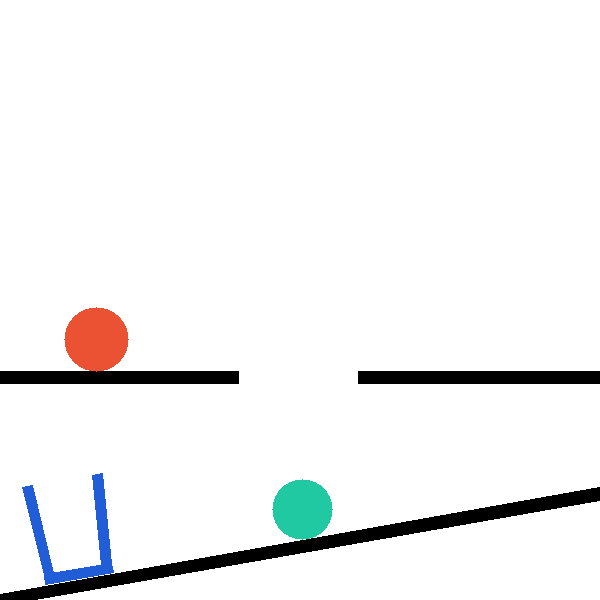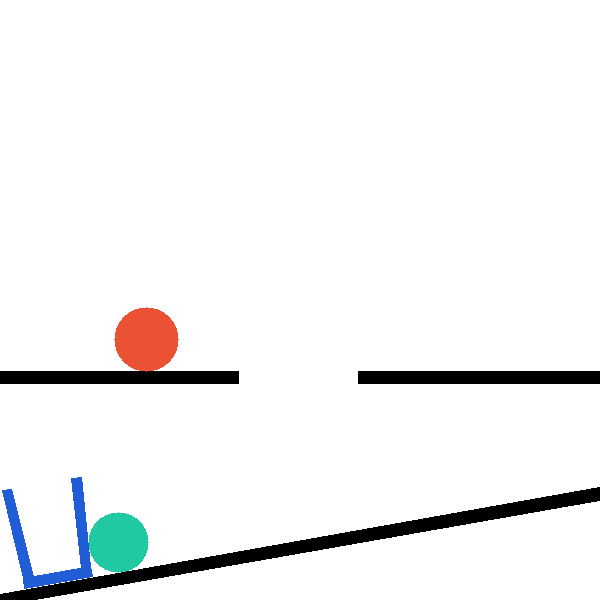
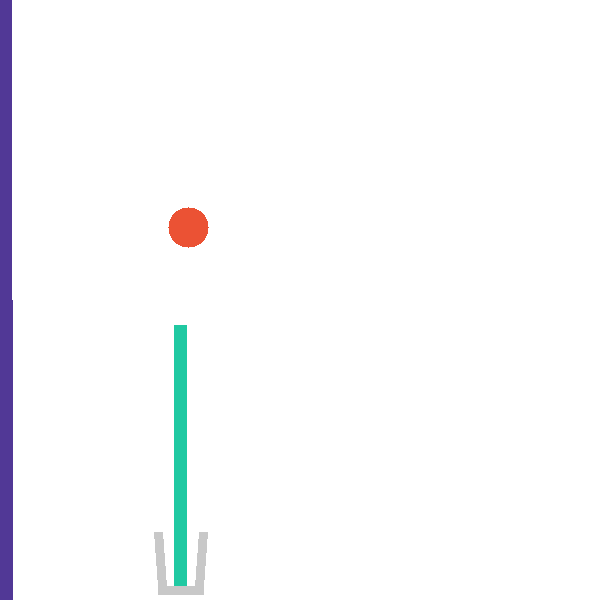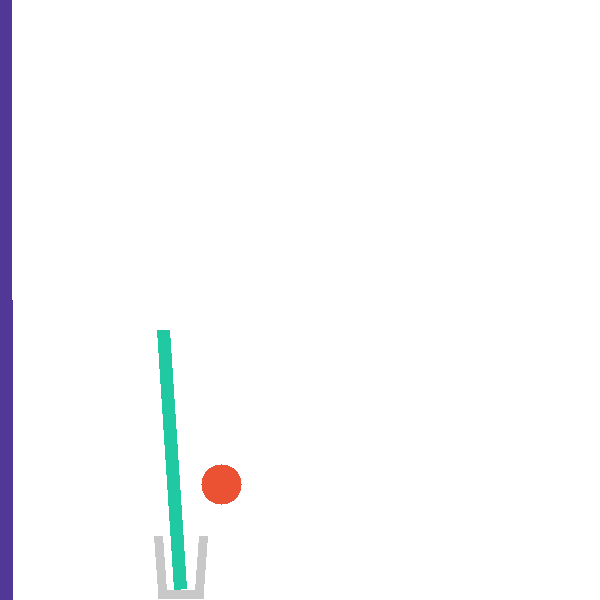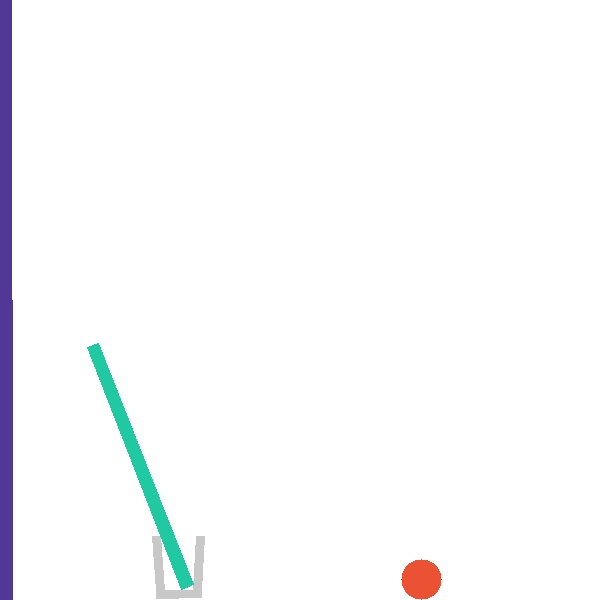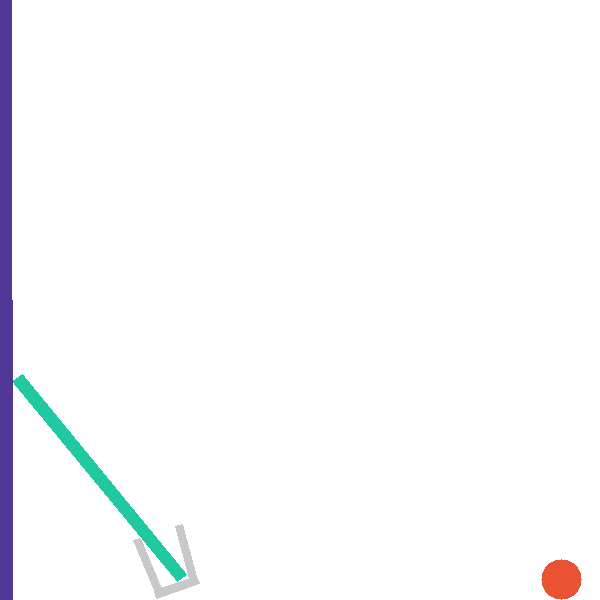
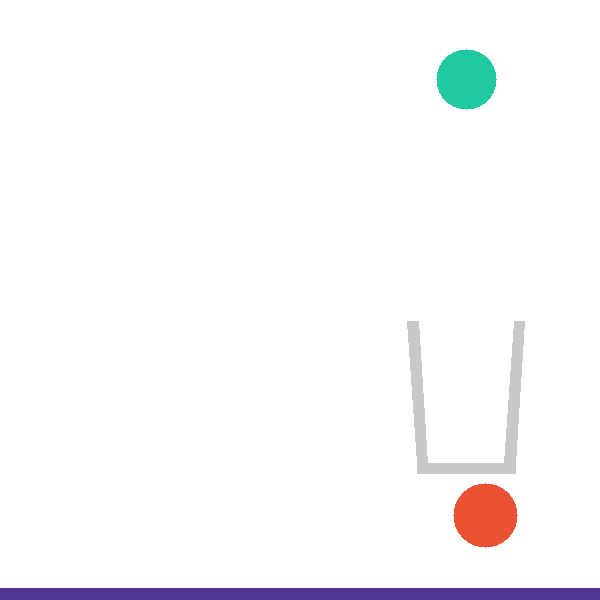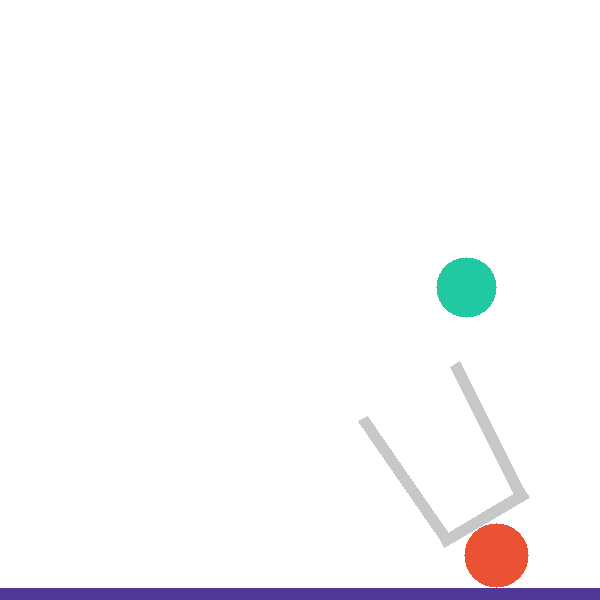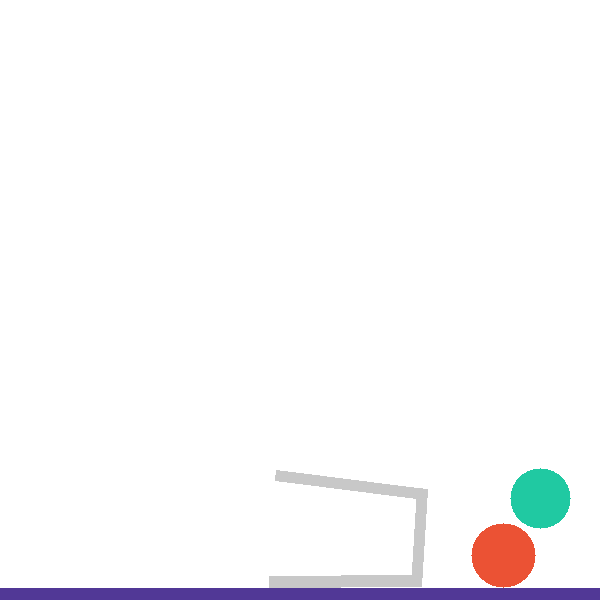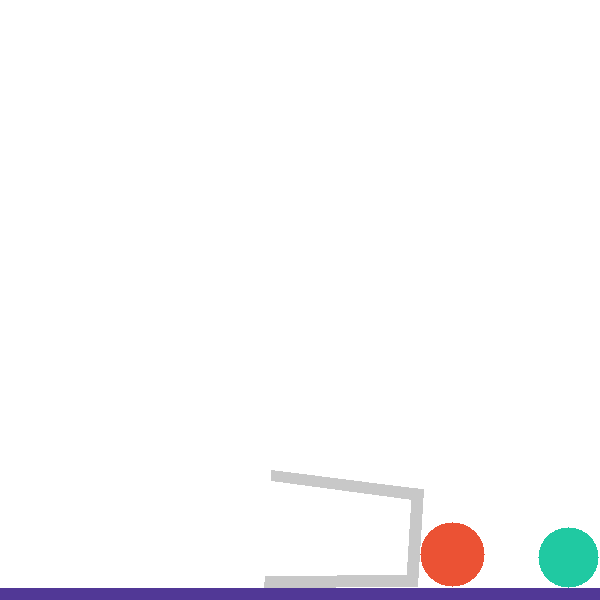
Each level exposes a structured tool surface the agent invokes directly, so that hypothesis testing is explicit and measurable. The catapult level, for example, exposes four complementary tools:
describe_scene_geometry()
# Strategy-neutral inventory: balls (pos, radius, dynamic),
# bars (centre, angle, length), baskets, key pairwise distances,
# and the success condition. A first-pass survey.
predict_first_contact(x, y, radius)
# Cheap pre-check (≤90 steps): which object the red ball hits
# first, the contact step, approach speed, point, surface normal.
trace_green_ball(x, y, radius)
# Lightweight probe: green ball's (x,y) waypoints every 30 steps
# plus start/end/peak summary. "Where does it go?"
simulate_with_trace(x, y, radius, object_names, stop_step)
# Full rollout: per-object kinematic extrema (peak_y, v_max,
# Δpos, angular speed) + up to 15 contact events.
finish(x, y, radius)
# Commit the final placement; environment scores the predicate.
Other levels add bespoke analysis tools — compute_intercept_setup() (falling_into_place),
compute_basket_analysis() (basket_case), get_ramp_center() (pass_the_parcel).
The same backend exposes a snapshot/restore primitive that branches a shared
mid-trajectory state into paired counterfactual rollouts (paper Figure 13).
HExA instantiates a two-agent architecture operating over a sequence of rounds. An actor generates trajectories by interacting with the environment through the tool-call interface; an evolver reads batches of trajectories and distils them into a natural-language skill bank; and a retriever injects the top-weighted skills and common mistakes into the actor's context at the start of each new episode. Each subsequent trajectory benefits from the accumulated experience of all prior ones — in-context reinforcement learning, where the policy improves through context augmentation rather than weight updates.
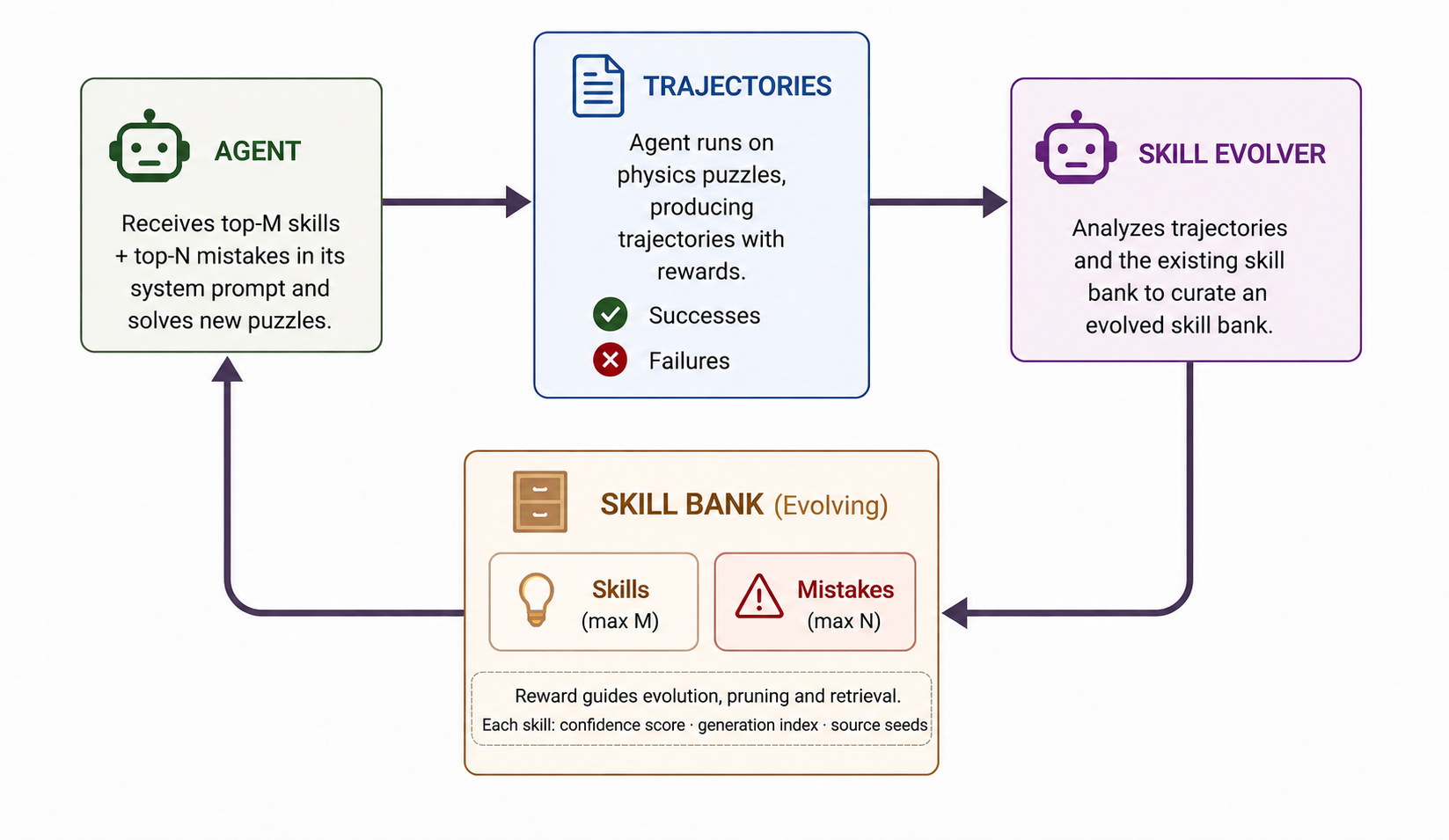
Each trajectory gets a scalar reward r(τ) ∈ [−1, +1] reflecting both outcome and efficiency — fast successes yield high-confidence strategies, while extensively-explored failures provide evidence for diagnosing mistakes. The evolver runs a two-pass distillation: first, contrastive skill extraction across the full batch (what distinguishes high-reward from low-reward trajectories); second, mistake and partial-skill extraction focused on the failure subset. Each skill carries a weight wk derived from the mean reward of its source trajectories.
Skills are hierarchical in two senses. First, they abstract many low-level tool calls into one high-level
principle (e.g. "when the ceiling–range tradeoff is unsolvable by radius tuning, shift x to
0.1–0.3" compresses dozens of (x, y, r) sequences). Second, skills are learned
while the agent already has access to earlier ones, so later skills build on earlier ones. The default
Off2On Evolving regime merges, revises, or prunes skills with each round's evidence; it
beats Iterative Replacement, frozen Offline banks, and Pure Online across every model and level tested.
Given source banks and a textual description of a target task, the evolver identifies structurally relevant skills, re-grounds them in the target task, and recalibrates their weights by how directly the principle transfers — enabling zero-shot transfer with no target-task trajectories. A transferred bank can also seed subsequent within-task refinement.
Catapult, seed 45. ReAct (no memory) exhausts its 25-iteration budget re-searching placements and never finds a working launch. HExA reuses skills distilled from earlier catapult episodes — it already knows how to launch (drop a heavy ball on the arm) and how to fix the usual failure (when the shot arcs too high and hits the ceiling, shift the drop point sideways to flatten it). After one ceiling overshoot it applies the learned correction and solves the level.

On the hardest levels, turning interaction traces into an evolving skill bank far outperforms ReAct, Reflexion, and a no-tool baseline — while using fewer iterations per episode.
Removing reward weighting from the evolver collapses much of the gain, showing the improvement comes from scoring and reusing skills, not merely interacting more.
The same mechanism lifts smaller open models, not just a strong frontier prior — the skill bank is a general in-context adaptation mechanism.
Banks synthesised from easier source levels solve an unseen harder level with no target-level experimentation, evidence the evolver extracts abstract physics primitives.
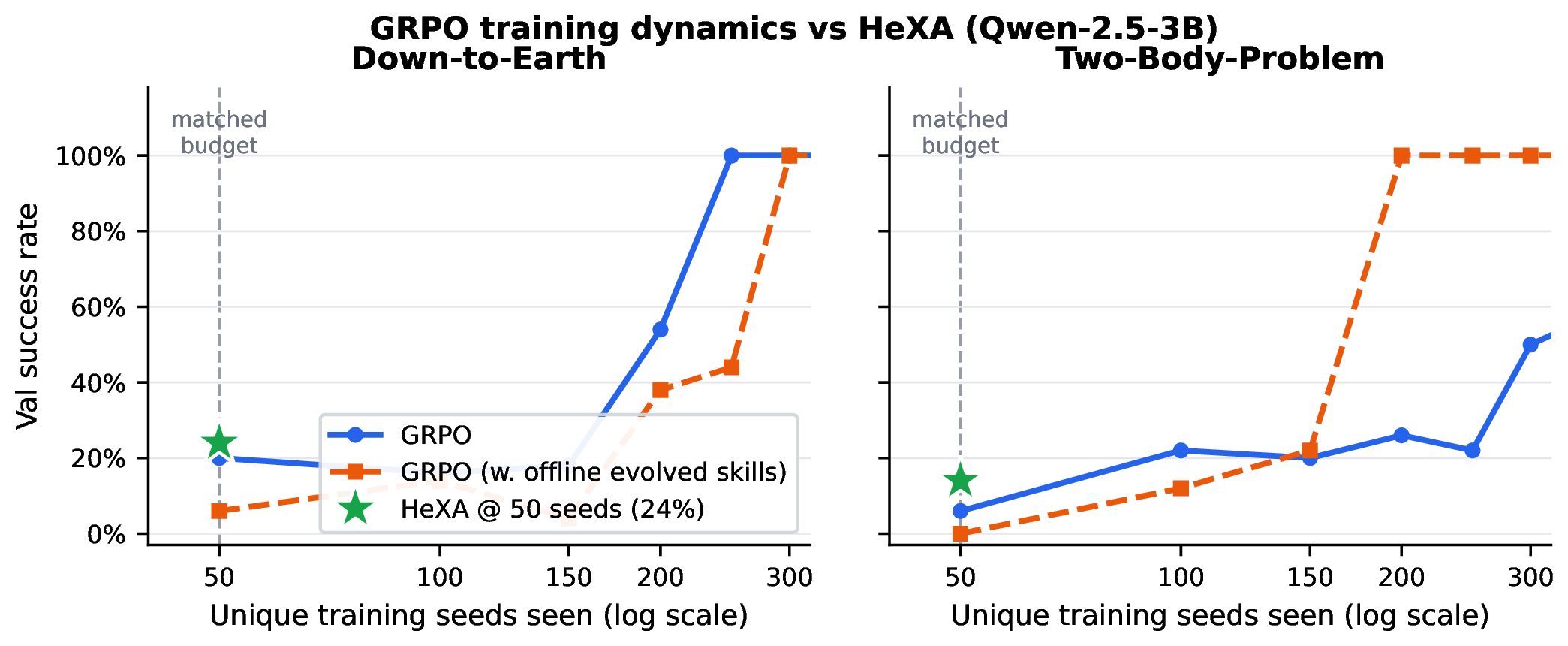
At a matched 50-seed budget, in-context HExA beats GRPO fine-tuning, because a discovered strategy is usable by the next episode immediately via context.
A 2D physics domain whose tasks can't be read off a static description, with a controllable difficulty range and a programmatic intervention API.
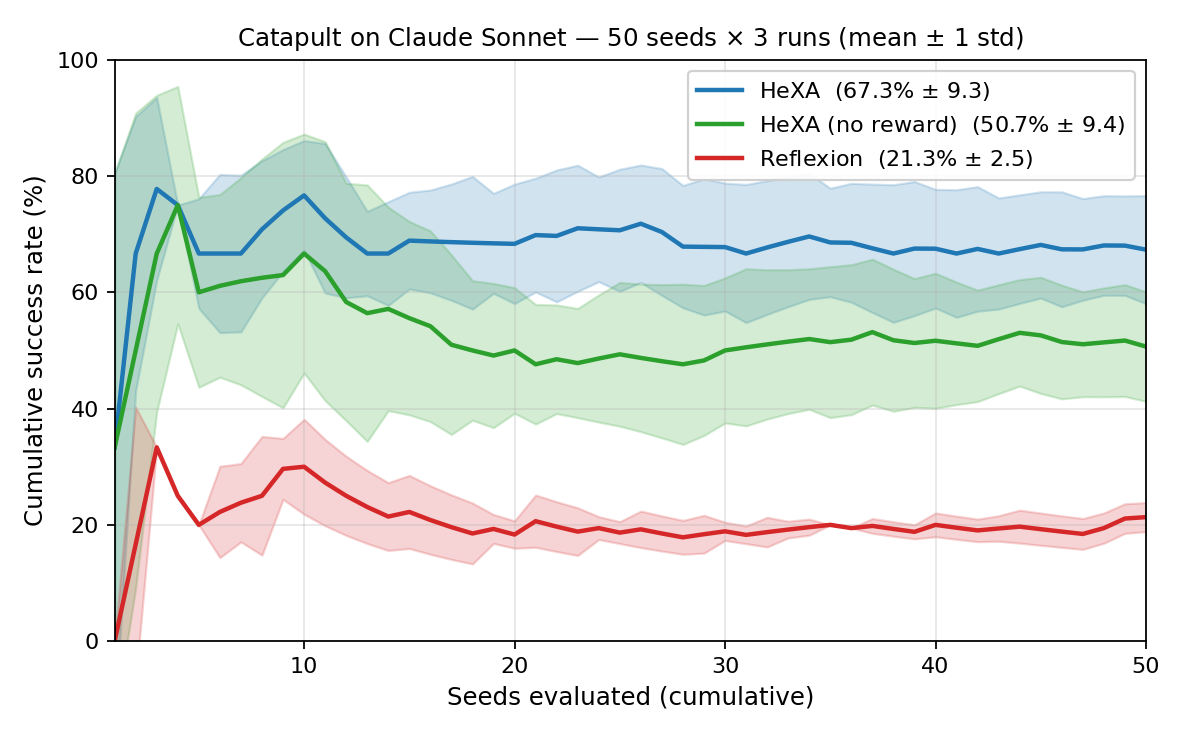
All methods are evaluated on the same 50 seeds per level (paired comparisons), under an identical 25-iteration harness, with HExA in its default Off2On Evolving configuration (x=3 seeds/round). HExA, HExA (no reward), and Reflexion report mean ± std over 3 runs.
catapult (Claude Sonnet 4.6, 50 seeds)| Method | Acc. (%) | Succ. | Fail | Avg Iter |
|---|---|---|---|---|
| Direct (one-shot, no tools) | 2.0 | 1 | 49 | 1.0 |
| ReAct baseline | 8.0 | 4 | 46 | 22.9 |
| Reflexion (K=2, 3 runs) | 21.3 ± 2.5 | 10.7 | 39.3 | 21.2 |
| HExA (no reward, 3 runs) | 50.7 ± 9.4 | 25.3 | 24.7 | 16.5 |
| HExA (Off2On Evol., 3 runs) | 67.3 ± 9.3 | 33.7 | 16.3 | 14.4 |
HExA reaches ~3× the strongest baseline (Reflexion) and uses the fewest iterations per solve.
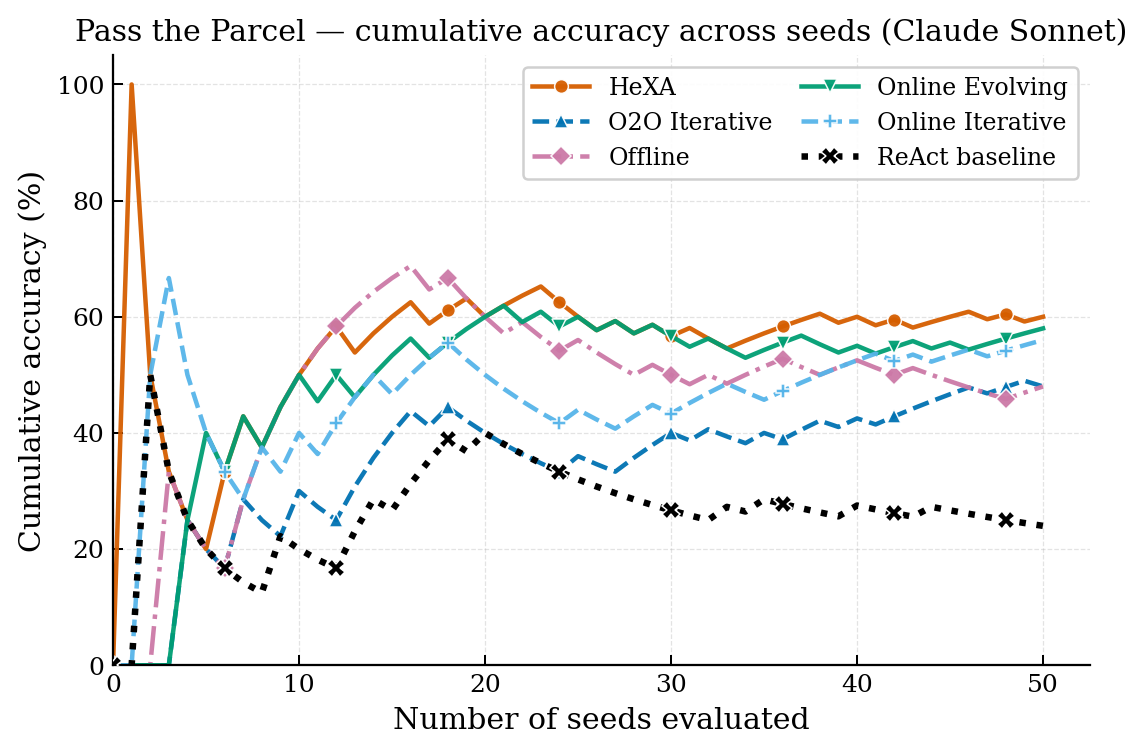
On pass_the_parcel, the best HExA config reaches 60% vs. 24% (ReAct),
16% (Reflexion), 0% (Direct).
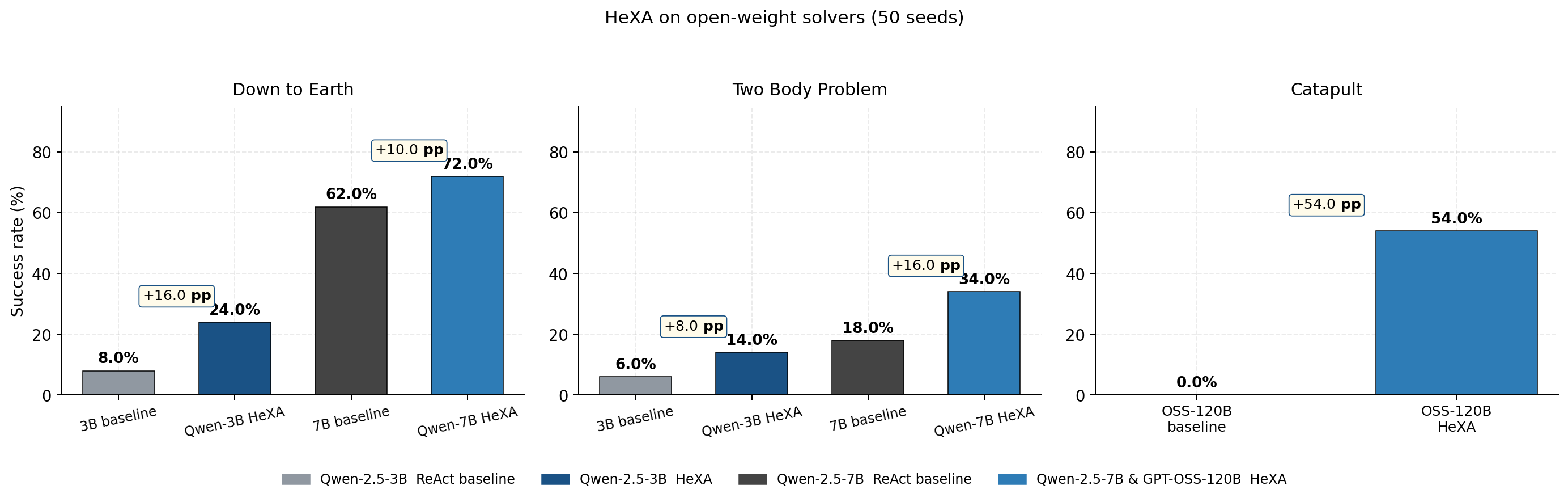
| Level | Method | Acc. (%) | Avg Iters | Δ |
|---|---|---|---|---|
| Down to Earth | ReAct baseline | 62.0 | 12.5 | — |
| HExA (no reward) | 64.0 | 14.8 | +2.0 | |
| HExA (reward-weighted) | 72.0 | 12.6 | +10.0 | |
| Two Body Problem | ReAct baseline | 18.0 | 22.2 | — |
| HExA (no reward) | 26.0 | 22.2 | +8.0 | |
| HExA (reward-weighted) | 34.0 | 18.9 | +16.0 |
| Level | Model | Baseline | HExA | Δ |
|---|---|---|---|---|
| Down to Earth | Qwen-2.5-3B | 8.0 | 24.0 | +16.0 |
| Down to Earth | Qwen-2.5-7B | 62.0 | 72.0 | +10.0 |
| Two Body Problem | Qwen-2.5-3B | 6.0 | 14.0 | +8.0 |
| Two Body Problem | Qwen-2.5-7B | 18.0 | 34.0 | +16.0 |
| Catapult | GPT-OSS-120B | 0.0 | 54.0 | +54.0 |
At a matched budget of 50 unique seeds, HExA beats GRPO fine-tuning: 24% vs 20% on down_to_earth and 14% vs 6% on two_body_problem. A strategy HExA discovers is usable by the next episode immediately via context, whereas GRPO must encode it into weights over many rollouts. With sufficient training, GRPO eventually catches up via direct reward optimisation.
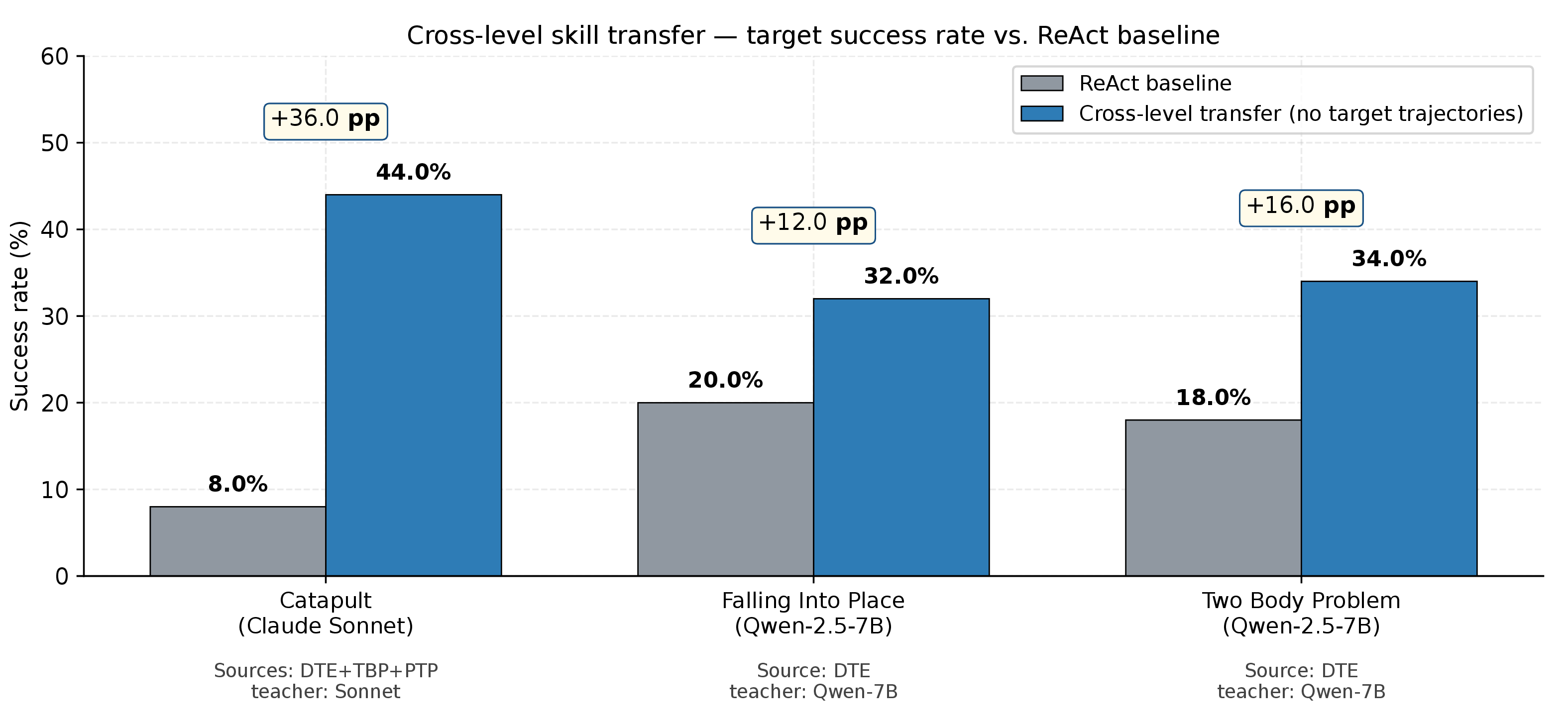
Do distilled skills encode genuine physics primitives or just level-specific recipes? We test this by synthesising a skill bank for a target level using only source-level banks and a one-sentence level description — no target-level trajectories at any stage.
| Target Level | Sources | Model | ReAct | Transfer | Δ |
|---|---|---|---|---|---|
| Catapult | DTE + TBP + PTP | Sonnet | 8.0% | 44.0% | +36 pp |
| Falling Into Place | DTE only | Qwen-7B | 20.0% | 32.0% | +12 pp |
| Two Body Problem | DTE only | Qwen-7B | 18.0% | 34.0% | +16 pp |
Transfer is positive in every case. No target-level trajectories are seen at any stage.
After each round of experimentation, HExA's evolver distils interaction trajectories into a growing library of physics principles and anti-patterns. Each skill carries a confidence score computed from the rewards of the trajectories it was extracted from — higher-confidence skills appear at the top of every agent's context. Below are real entries from evolved banks across three InterPhyre levels.
Placing the red ball at x=0.5 on the catapult arm produces a consistent rightward launch arc. The contact point sits on the right side of the pivot, creating sufficient lever arm for strong rotation while staying in the geometrically stable zone. Only deviate to x=0.3 when a ceiling hit is observed.
(0.5, 0.4, 1.5) — canonical primary (Seed 44)
The catapult arm is a lever — red ball mass (∝r³) determines angular momentum imparted to the arm. Below r≈1.2 the arm rotates too slowly to launch the green ball across the ∼7-unit gap. r=1.5 is the minimum reliable threshold; r=2.0 adds negligible additional range at x=0.5 due to arm rotation saturation.
(0.5, 0.4, 1.5) — Seed 44
When primary (x=0.5, y=0.4, r=1.5) fails: (1) ceiling hit → try x=0.3, y=0.4, r=1.5; if still hitting, try x=0.3, y=−0.3, r=2.0 but verify no overlap first. (2) short range → increase y to 0.9 or shift x to 0.4–0.45. (3) persistent failure after 2+ radius variations at same x → stop tuning, shift x to 0.2–0.3.
Shifting x from 0.5 to 0.3 flattens the launch arc by changing the arm contact point — this x-shift is the primary ceiling-escape mechanism, not lowering y. When x=0.3, y=−0.3, r=2.0 is invalid due to gray_ball pivot overlap, use x=0.3, y=0.4, r=1.5; y=0.4 avoids the overlap zone while preserving arc-flattening.
The static black ball near y≈4.6 varies in x-position across seeds (x≈−3.85 to −1.14). When the blocker is at x > −2.5, primary placement causes a ceiling hit. When x < −3.5, x=0.3 launches allow the green ball to arc up and bounce off the top wall before descending into the basket.
Micro-tuning x/y/r around the same narrow region without escaping the local solution space.
Increasing radius at fixed x=0.5 expecting more range, when arm rotation is already saturated.
Adjusting y upward after a ceiling hit — increasing launch energy, worsening the collision.
Place the red ball near the green ball but not overlapping to ensure a precise collision. Proximity maximises impulse transfer while avoiding invalid placements that waste iterations.
Place the red ball closer to the green ball and near the edge of the platform to ensure a strong and directed collision impulse. Proximity to the platform edge increases the lateral component of the impulse, helping the green ball clear the edge rather than bouncing back.
(1.3, 2.5)
Ensure the red ball is placed near the edge of the platform to maximise the collision impulse toward the edge. The platform boundary creates a geometry where a well-placed red ball can leverage the edge to redirect the green ball downward rather than laterally.
(1.5, 3.5)
Repeatedly trying the red ball in the same crowded area around the green ball after each failure.
Ignoring the direction and magnitude of the collision impulse when choosing placement.
Place the red ball on the upper portion of the ramp at x ≈ ramp_center_x − 0.15 to −0.50 and y ≈ 3.8–4.2. This offset ensures the ball rolls down the ramp with sufficient leftward momentum to strike the top basket. The exact x-offset modulates the angle of impact on the inverted basket.
Radii below 0.40 often produce insufficient impulse to dislodge the top basket. Radii above 0.52 frequently overshoot the green ball far left (x < −3.0), missing the bottom basket entirely. The r=0.45–0.52 range provides the best impulse-accuracy tradeoff.
Setting y=4.2 provides reliable impulse for both r=0.45 and r=0.5. Trajectories at y=4.0 frequently leave the green ball energy-deficient, stalling above the bottom basket. y=4.2 consistently cleared this gap in successful runs; y=4.3 is the fallback for persistent energy deficit.
When the top basket and green ball share nearly identical velocities during descent (green_y − basket_y < 0.6), the basket is re-trapping the green ball. A large x-shift alone may not break this coupling — increasing y is often required to give the green ball enough velocity to separate from the basket mid-fall.
The level exhibits sharp non-monotonic thresholds: small radius changes (Δ≈0.05–0.1) can flip the green ball from rim-stall to far-overshoot without passing through a success region. When r=0.5 produces rim stall and r=0.7 produces far overshoot, intermediate radii typically also stall. Switch to adjusting y rather than bisecting r.
Fine-grained bisection of radius or y in chaotic threshold regions where physics is non-monotonic.
Failing to prevent the top basket from tracking alongside the green ball and re-trapping it mid-fall.
Ignoring the 2000-step budget — green ball has the right direction but insufficient speed to reach the target.
@article{hexa2026,
title = {HExA:@misc{chandra2026hierarchicalexperimentalistagents,
title={Hierarchical Experimentalist Agents},
author={Abhranil Chandra and Sankaran Vaidyanathan and Utsav Dhanuka and Varun Gandhi and Scott Niekum},
year={2026},
eprint={2606.29315},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2606.29315},
}